알려진 바와 같이, 확률변수의 분포 법칙은 다양한 방식으로 지정될 수 있습니다. 이산 확률변수는 분포 계열이나 적분 함수를 사용하여 지정할 수 있으며, 연속 확률 변수는 적분 함수나 미분 함수를 사용하여 지정할 수 있습니다. 이 두 기능의 선택적 유사점을 고려해 보겠습니다.
임의의 볼륨 변수 값의 샘플 세트가 있다고 가정합니다.  이 세트의 각 옵션은 해당 빈도와 연관되어 있습니다. 더 보자
이 세트의 각 옵션은 해당 빈도와 연관되어 있습니다. 더 보자  는 실수이고,
는 실수이고,  – 확률변수의 표본값 개수
– 확률변수의 표본값 개수  , 더 작은
, 더 작은  .그럼 번호는
.그럼 번호는  표본에서 관찰된 수량 값의 빈도입니다. 엑스, 더 작은
표본에서 관찰된 수량 값의 빈도입니다. 엑스, 더 작은  ,
저것들. 사건 발생 빈도
,
저것들. 사건 발생 빈도  . 변경할 때 엑스일반적인 경우에는 값도 변경됩니다.
. 변경할 때 엑스일반적인 경우에는 값도 변경됩니다.  . 이는 상대빈도가
. 이는 상대빈도가  인수의 함수이다
인수의 함수이다  . 그리고 이 기능은 실험 결과 얻은 샘플 데이터에서 찾아낸 것이므로 선택적(selective) 또는 경험적.
. 그리고 이 기능은 실험 결과 얻은 샘플 데이터에서 찾아낸 것이므로 선택적(selective) 또는 경험적.
정의 10.15. 경험적 분포 함수(샘플링 분포 함수)는 다음과 같습니다.  , 각 값에 대해 정의 엑스사건의 상대빈도
, 각 값에 대해 정의 엑스사건의 상대빈도  .
.
 (10.19)
(10.19)
경험적 샘플링 분포 함수와 달리 분포 함수는 에프(엑스) 일반 인구의 호출 이론적 분포 함수. 그들 사이의 차이점은 이론적 기능 에프(엑스)
사건의 확률을 결정한다  , 그리고 경험적인 것은 동일한 사건의 상대 빈도입니다. 베르누이의 정리로부터 다음과 같다
, 그리고 경험적인 것은 동일한 사건의 상대 빈도입니다. 베르누이의 정리로부터 다음과 같다
 ,
,
 (10.20)
(10.20)
저것들. 전체적으로  개연성
개연성  이벤트의 상대 빈도
이벤트의 상대 빈도  , 즉.
, 즉.  서로 조금씩 다릅니다. 따라서 일반 모집단의 이론적(적분) 분포 함수를 근사화하기 위해 표본의 경험적 분포 함수를 사용하는 것이 좋습니다.
서로 조금씩 다릅니다. 따라서 일반 모집단의 이론적(적분) 분포 함수를 근사화하기 위해 표본의 경험적 분포 함수를 사용하는 것이 좋습니다.
기능  그리고
그리고  동일한 속성을 가지고 있습니다. 이는 함수 정의에 따른 것입니다.
동일한 속성을 가지고 있습니다. 이는 함수 정의에 따른 것입니다. 
속성  :
:

예제 10.4.주어진 표본 분포를 기반으로 경험적 함수를 구성합니다.
|
옵션 | |||
|
주파수 |


해결책:표본 크기를 찾아보자 N=
12+18+30=60. 가장 작은 옵션  , 따라서,
, 따라서,  ~에
~에  . 의미
. 의미  , 즉
, 즉  12번 관찰되었으므로 다음과 같습니다.
12번 관찰되었으므로 다음과 같습니다.
 =
= ~에
~에  .
.
의미 엑스<
10, 즉  그리고
그리고  12+18=30번 관찰되었으므로,
12+18=30번 관찰되었으므로,  =
= ~에
~에  . ~에
. ~에 
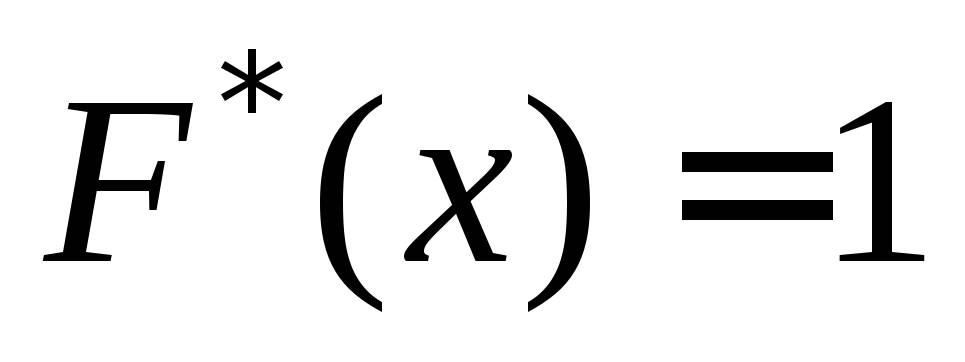 .
.
필요한 경험적 분포 함수:
 =
=
일정  그림에 표시됩니다. 10.2
그림에 표시됩니다. 10.2
아르 자형  이다. 10.2
이다. 10.2
보안 질문
1. 수학적 통계는 어떤 주요 문제를 해결합니까? 2. 일반 모집단과 표본 모집단? 3. 표본 크기를 정의합니다. 4. 대표 샘플은 무엇입니까? 5. 대표성의 오류. 6. 샘플링의 기본 방법. 7. 주파수, 상대빈도의 개념. 8. 통계 계열의 개념. 9. Sturges 공식을 적어보세요. 10. 샘플 범위, 중앙값 및 모드의 개념을 공식화합니다. 11. 빈도 다각형, 히스토그램. 12. 표본 모집단의 점추정 개념. 13. 편향되고 편향되지 않은 점 추정. 14. 표본 평균의 개념을 공식화합니다. 15. 표본 분산의 개념을 공식화합니다. 16. 표본 표준편차의 개념을 공식화합니다. 17. 표본 변동 계수의 개념을 공식화합니다. 18. 표본 기하 평균의 개념을 공식화합니다.
강의 13. 확률변수의 통계적 추정의 개념
정량적 특성 X의 통계적 빈도 분포를 특성 값이 x보다 작은 것으로 관찰된 관찰 수로 표시하고 총 관찰 수를 n으로 표시하겠습니다. 분명히, 사건 X의 상대적 빈도는< x равна и является функцией x. Так как эта функция находится эмпирическим (опытным) путем, то ее называют эмпирической.
경험적 분포 함수(샘플링 분포 함수)는 각 값 x에 대해 이벤트 X의 상대 빈도를 결정하는 함수입니다.< x. Таким образом, по определению ,где - число вариант, меньших x, n – объем выборки.
표본의 경험적 분포 함수와 달리 모집단 분포 함수는 다음과 같습니다. 이론적 분포 함수.이들 함수의 차이점은 이론적 함수가 다음을 결정한다는 것입니다. 개연성이벤트X< x, тогда как эмпирическая – 상대도수같은 이벤트.
n이 증가함에 따라 사건 X의 상대 빈도는< x, т.е. стремится по вероятности к вероятности этого события. Иными словами
경험적 분포 함수의 속성:
1) 경험적 함수의 값은 세그먼트에 속합니다
2) - 비감소 기능
3) 가 가장 작은 옵션이면 에 대해 = 0이고, 가 가장 큰 옵션이면 에 대해 = 1입니다.
표본의 경험적 분포함수는 모집단의 이론적 분포함수를 추정하는 역할을 합니다.
예. 표본 분포를 기반으로 경험적 함수를 구성해 보겠습니다.
| 옵션 | |||
| 주파수 |
표본 크기를 찾아보겠습니다: 12+18+30=60. 가장 작은 옵션은 2이므로 x £ 2에 대해 =0입니다. x의 값<6, т.е. , наблюдалось 12 раз, следовательно, =12/60=0,2 при 2< x £6. Аналогично, значения X < 10, т.е. и наблюдались 12+18=30 раз, поэтому =30/60 =0,5 при 6< x £10. Так как x=10 – наибольшая варианта, то =1 при x>10. 따라서 원하는 경험적 함수는 다음과 같은 형식을 갖습니다.
통계 추정의 가장 중요한 속성
일반 인구의 양적 특성을 연구하는 것이 필요하다고 가정해 보겠습니다. 이론적 고려로부터 다음을 확립하는 것이 가능했다고 가정해보자. 정확히 어느 것입니까?분포에는 부호가 있으며 이를 결정하는 매개변수를 추정하는 것이 필요합니다. 예를 들어, 연구 중인 특성이 모집단에 정규 분포를 따르는 경우 수학적 기대값과 표준 편차를 추정해야 합니다. 특성에 포아송 분포가 있는 경우 매개변수 l을 추정해야 합니다.
일반적으로 n개의 독립적인 관찰 결과로 얻은 정량적 특성 값과 같은 샘플 데이터만 사용할 수 있습니다. 독립 확률 변수를 고려하면 다음과 같이 말할 수 있습니다. 이론적 분포의 알 수 없는 매개변수에 대한 통계적 추정치를 찾는다는 것은 추정된 매개변수의 대략적인 값을 제공하는 관측 확률 변수의 함수를 찾는 것을 의미합니다. 예를 들어, 정규 분포의 수학적 기대값을 추정하기 위해 함수의 역할은 산술 평균에 의해 수행됩니다.
통계적 추정이 추정된 매개변수의 정확한 근사치를 제공하려면 특정 요구 사항을 충족해야 하며, 그 중 가장 중요한 요구 사항은 다음과 같습니다. 이주되지 않은 그리고 용해력 평가.
이론적 분포의 알려지지 않은 매개변수에 대한 통계적 추정치를 구해 보겠습니다. 크기 n의 표본에서 추정값을 구해 보겠습니다. 실험을 반복해 보겠습니다. 일반 모집단에서 동일한 크기의 또 다른 표본을 추출하고 해당 데이터를 기반으로 다른 추정치를 얻습니다. 실험을 여러 번 반복하면 다른 숫자가 나옵니다. 점수는 무작위 변수로 생각할 수 있고 숫자는 가능한 값으로 생각할 수 있습니다.
추정치가 대략적인 값을 제공하는 경우 풍부하게, 즉. 각 숫자는 실제 값보다 크며 결과적으로 확률 변수의 수학적 기대값(평균값)은 다음보다 큽니다. 마찬가지로 견적을 내보면 단점이 있는, 저것 .
따라서 수학적 기대값이 추정된 매개변수와 동일하지 않은 통계적 추정값을 사용하면 체계적인(동일한 부호의) 오류가 발생할 수 있습니다. 반대로, 이는 체계적인 오류를 방지합니다.
편견 없음 통계적 추정치라고 하며, 수학적 기대치는 모든 표본 크기에 대한 추정된 매개변수와 동일합니다.
난민이 조건을 만족하지 않는 추정치라고 합니다.
가능한 값은 매우 흩어져 평균값 주위, 즉 그 차이는 상당할 수 있습니다. 이 경우, 예를 들어 한 샘플의 데이터에서 찾은 추정치는 평균값과 크게 떨어져 추정되는 매개변수와 크게 다를 수 있습니다.
효과적인 주어진 표본 크기 n에 대해 다음을 갖는 통계적 추정치입니다. 가능한 가장 작은 차이 .
대규모 표본을 고려할 때 통계적 추정이 필요합니다. 용해력 .
풍부한 통계적 추정이라고 하며, n®\은 확률적으로 추정된 매개변수에 대한 경향이 있습니다. 예를 들어, 편향되지 않은 추정의 분산이 n®\로 0이 되는 경향이 있으면 그러한 추정은 일관성이 있는 것으로 나타납니다.
경험적 분포 함수의 결정
$X$를 랜덤 변수로 둡니다. $F(x)$는 주어진 확률변수의 분포함수입니다. 동일한 조건에서 서로 독립적으로 주어진 확률 변수에 대해 $n$ 실험을 수행합니다. 이 경우 샘플이라고 하는 일련의 값 $x_1,\ x_2\ $, ... ,$\ x_n$을 얻습니다.
정의 1
각 값 $x_i$ ($i=1,2\ $, ... ,$ \ n$)을 변형이라고 합니다.
이론적 분포 함수의 한 가지 추정치는 경험적 분포 함수입니다.
정의 3
경험적 분포 함수 $F_n(x)$는 각 값 $x$에 대해 사건의 상대 빈도 $X \를 결정하는 함수입니다.
여기서 $n_x$는 $x$보다 작은 옵션의 수이고, $n$은 샘플 크기입니다.
경험적 함수와 이론적 함수의 차이점은 이론적 함수가 사건 $X의 확률을 결정한다는 것입니다.
경험적 분포 함수의 속성
이제 분포 함수의 몇 가지 기본 속성을 고려해 보겠습니다.
$F_n\left(x\right)$ 함수의 범위는 $$ 세그먼트입니다.
$F_n\left(x\right)$는 비감소 함수입니다.
$F_n\left(x\right)$는 왼쪽 연속 함수입니다.
$F_n\left(x\right)$는 조각별 상수 함수이며 확률 변수 $X$의 값 지점에서만 증가합니다.
$X_1$을 가장 작은 변형으로, $X_n$을 가장 큰 변형으로 설정합니다. 그런 다음 $(x\le X)_1$에 대해 $F_n\left(x\right)=0$ 및 $x\ge X_n$에 대해 $F_n\left(x\right)=1$.
이론적 기능과 경험적 기능을 연결하는 정리를 소개하겠습니다.
정리 1
$F_n\left(x\right)$를 경험적 분포 함수로 하고 $F\left(x\right)$를 일반 표본의 이론적 분포 함수로 둡니다. 그러면 평등은 다음과 같이 유지됩니다.
\[(\mathop(lim)_(n\to \infty ) (|F)_n\left(x\right)-F\left(x\right)|=0\ )\]
경험적 분포함수를 찾는 문제의 예
실시예 1
샘플링 분포에 테이블을 사용하여 다음 데이터가 기록되도록 합니다.
그림 1.
표본 크기를 찾고, 경험적 분포 함수를 생성하고 도표화합니다.
샘플 크기: $n=5+10+15+20=50$.
속성 5에 따르면 $x\le 1$ $F_n\left(x\right)=0$ 및 $x>4$ $F_n\left(x\right)=1$에 대해 해당 값이 있습니다.
$x 가치
$x 가치
$x 가치
따라서 우리는 다음을 얻습니다:

그림 2.

그림 3.
실시예 2
20개 도시는 러시아 중부 도시에서 무작위로 선택되었으며, 이에 대한 대중교통 요금에 대한 다음 데이터가 수집되었습니다: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15, 14 , 15, 13, 13, 12, 12, 15, 14, 14.
이 표본에 대한 경험적 분포 함수를 만들고 플롯합니다.
샘플 값을 오름차순으로 적고 각 값의 빈도를 계산해 보겠습니다. 우리는 다음 표를 얻습니다.
그림 4.
샘플 크기: $n=20$.
속성 5에 따르면 $x\le 12$ $F_n\left(x\right)=0$ 및 $x>15$ $F_n\left(x\right)=1$에 대해 해당 값이 있습니다.
$x 가치
$x 가치
$x 가치
따라서 우리는 다음을 얻습니다:

그림 5.
경험적 분포를 그려보겠습니다.

그림 6.
독창성: $92.12\%$.
실험식이 무엇인지 알아보세요.화학에서 EP는 화합물을 설명하는 가장 간단한 방법입니다. 기본적으로 화합물을 구성하는 요소의 백분율을 기준으로 한 목록입니다. 이 간단한 공식은 설명하지 않는다는 점에 유의해야 합니다. 주문하다화합물의 원자는 단순히 그것이 어떤 원소로 구성되어 있는지를 나타냅니다. 예를 들어:
- 40.92%의 탄소로 구성된 화합물; 4.58% 수소와 54.5% 산소는 실험식 C 3 H 4 O 3 을 갖게 됩니다(이 화합물의 EF를 찾는 방법에 대한 예는 두 번째 부분에서 논의됩니다).
"백분율 구성"이라는 용어를 이해합니다."백분율 구성"은 해당 화합물 전체에서 각 개별 원자의 백분율입니다. 화합물의 실험식을 찾으려면 해당 화합물의 조성 비율을 알아야 합니다. 숙제에 대한 경험적 공식을 찾고 있다면 백분율이 주어질 가능성이 높습니다.
- 실험실에서 화합물의 백분율 구성을 확인하려면 몇 가지 물리적 실험을 거친 다음 정량 분석을 거쳐야 합니다. 실험실에 있지 않는 한 이러한 실험을 수행할 필요는 없습니다.
그램 원자를 다루어야 한다는 점을 명심하세요.그램 원자는 질량이 원자 질량과 같은 물질의 특정 양입니다. 그램 원자를 찾으려면 다음 방정식을 사용해야 합니다. 화합물의 원소 비율은 원소의 원자 질량으로 나뉩니다.
- 예를 들어, 40.92%의 탄소를 함유한 화합물이 있다고 가정해 보겠습니다. 탄소의 원자 질량은 12이므로 방정식은 40.92 / 12 = 3.41이 됩니다.
원자 비율을 찾는 방법을 알아보세요.화합물로 작업할 때 1그램 이상의 원자가 생성됩니다. 화합물의 모든 그램 원자를 찾은 후 살펴보십시오. 원자 비율을 찾으려면 계산한 가장 작은 그램-원자 값을 선택해야 합니다. 그런 다음 모든 그램 원자를 가장 작은 그램 원자로 나누어야 합니다. 예를 들어:
- 3개의 그램 원자를 포함하는 화합물로 작업한다고 가정해 보겠습니다. 1.5; 2와 2.5. 이 숫자 중 가장 작은 숫자는 1.5입니다. 따라서 원자의 비율을 구하려면 모든 숫자를 1.5로 나누고 그 사이에 비율 기호를 넣어야 합니다. : .
- 1.5 / 1.5 = 1. 2 / 1.5 = 1.33. 2.5 / 1.5 = 1.66. 따라서 원자의 비율은 1: 1,33: 1,66 .
원자비 값을 정수로 변환하는 방법을 이해합니다.경험식을 작성할 때는 정수를 사용해야 합니다. 이는 1.33과 같은 숫자를 사용할 수 없음을 의미합니다. 원자의 비율을 찾은 후에는 분수(예: 1.33)를 정수(예: 3)로 변환해야 합니다. 이렇게 하려면 정수를 얻을 수 있는 원자 비율의 각 숫자를 곱하여 정수를 찾아야 합니다. 예를 들어:
- 2를 시도해 보세요. 원자비 숫자(1, 1.33, 1.66)에 2를 곱하면 2, 2.66, 3.32가 됩니다. 이는 정수가 아니므로 2는 적절하지 않습니다.
- 3을 시도해 보세요. 1, 1.33, 1.66에 3을 곱하면 각각 3, 4, 5가 됩니다. 따라서 정수의 원자비는 다음과 같은 형식을 갖습니다. 3: 4: 5 .